Quickstart¶
VIABEL currently supports both standard KL-based variational inference (KLVI) and chi-squared variational inference (CHIVI). Models are provided as Autograd-compatible log densities or can be constructed from PyStan fit objects.
As a simple example, we consider Neal’s funnel distribution in 2 dimensions so that we can visualize the results.
[1]:
import autograd.numpy as np
import autograd.scipy.stats.norm as norm
D = 2 # number of dimensions
log_sigma_stdev = 1. # 1.35
def log_density(x):
mu, log_sigma = x[:, 0], x[:, 1]
sigma_density = norm.logpdf(log_sigma, 0, log_sigma_stdev)
mu_density = norm.logpdf(mu, 0, np.exp(log_sigma))
return sigma_density + mu_density
Black-box Variational Inference¶
VIABEL’s bbvi function provides reasonable defaults: the objective is the ELBO (i.e., the including Kullback-Leibler divergence), a mean-field Gaussian approximation family, and automated RMSProp with adaptive step reduction and stopping rule.
[6]:
from viabel import bbvi, MFStudentT
results = bbvi(D, log_density=log_density, learning_rate=0.5, n_iters=30000)
Using cached StanModel for weighted_lin_regression
average loss = 1.669 | R hat converged|: 60%|██████ | 18125/30000 [00:29<00:19, 623.53it/s]
Convergence reached at iteration 18125
average loss = 0.86764 | R hat converged|: 5%|▌ | 651/11874 [00:00<00:16, 660.99it/s]
Convergence reached at iteration 651
Gradient evaluation took 0 seconds
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Gradient evaluation took 0 seconds
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.03 seconds (Sampling)
0.07 seconds (Total)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.04 seconds (Sampling)
0.08 seconds (Total)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.05 seconds (Sampling)
0.09 seconds (Total)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.06 seconds (Sampling)
0.1 seconds (Total)
WARNING:pystan:20 of 2000 iterations ended with a divergence (1 %).
WARNING:pystan:Try running with adapt_delta larger than 0.98 to remove the divergences.
average loss = 0.72357 | R hat converged|: 6%|▌ | 682/11222 [00:01<00:16, 642.38it/s]
Convergence reached at iteration 682
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Gradient evaluation took 0 seconds
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.02 seconds (Sampling)
0.06 seconds (Total)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.01 seconds (Sampling)
0.05 seconds (Total)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.02 seconds (Sampling)
0.06 seconds (Total)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.03 seconds (Sampling)
0.07 seconds (Total)
average loss = 0.61402 | R hat converged|: 23%|██▎ | 2443/10539 [00:03<00:12, 644.84it/s]
Convergence reached at iteration 2443
Gradient evaluation took 0 seconds
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Gradient evaluation took 0 seconds
1000 transitions using 10 leapfrog steps per transition would take 0 seconds.
Adjust your expectations accordingly!
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 1 / 1000 [ 0%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 100 / 1000 [ 10%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 200 / 1000 [ 20%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 300 / 1000 [ 30%] (Warmup)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 400 / 1000 [ 40%] (Warmup)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 500 / 1000 [ 50%] (Warmup)
Iteration: 501 / 1000 [ 50%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 600 / 1000 [ 60%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 700 / 1000 [ 70%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.03 seconds (Warm-up)
0.03 seconds (Sampling)
0.06 seconds (Total)
Iteration: 800 / 1000 [ 80%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.02 seconds (Sampling)
0.06 seconds (Total)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 900 / 1000 [ 90%] (Sampling)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.04 seconds (Warm-up)
0.02 seconds (Sampling)
0.06 seconds (Total)
Iteration: 1000 / 1000 [100%] (Sampling)
Elapsed Time: 0.05 seconds (Warm-up)
0.02 seconds (Sampling)
0.07 seconds (Total)
Termination rule reached at iteration 21901
Inefficiency Index: 1.1550993138293368
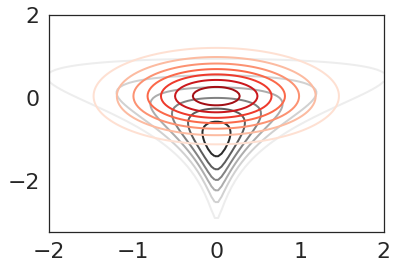
We can then plot contours the from the approximation Gaussian (red) and the target funnel distribution (black)
[7]:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white')
sns.set_context('notebook', font_scale=2, rc={'lines.linewidth': 2})
def plot_approx_and_exact_contours(log_density, approx, var_param,
xlim, ylim, cmap2='Reds'):
xlist = np.linspace(*xlim, 100)
ylist = np.linspace(*ylim, 100)
X, Y = np.meshgrid(xlist, ylist)
XY = np.concatenate([np.atleast_2d(X.ravel()), np.atleast_2d(Y.ravel())]).T
zs = np.exp(log_density(XY))
Z = zs.reshape(X.shape)
zsapprox = np.exp(approx.log_density(var_param, XY))
Zapprox = zsapprox.reshape(X.shape)
plt.contour(X, Y, Z, cmap='Greys', linestyles='solid')
plt.contour(X, Y, Zapprox, cmap=cmap2, linestyles='solid')
plt.xlim(xlim)
plt.ylim(ylim)
plt.show()
plot_approx_and_exact_contours(log_density, results['objective'].approx, results['opt_param'],
xlim=[-2, 2], ylim=[-3.25, 2])
Diagnostics¶
VIABEL also has a suite of diagostics for variational inference. We can easily run these using the vi_diagnostics function, although low-level support is also provided.
[8]:
from viabel import vi_diagnostics
import warnings
with warnings.catch_warnings():
warnings.simplefilter('ignore')
diagnostics = vi_diagnostics(results['opt_param'], objective=results['objective'], n_samples=100000)
Pareto k is estimated to be khat = 0.77
WARNING: khat > 0.7 means importance sampling is not feasible.
WARNING: not running further diagnostics
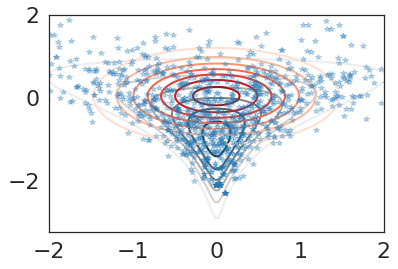
Importance Sampling¶
The Pareto-smoothed weights provide a fairly accuracy approximation.
[9]:
weights = np.exp(diagnostics['smoothed_log_weights'])
all_samples = diagnostics['samples']
# sample 1000 weights for visualization
subset = np.random.choice(all_samples.shape[1], size=1000, p=weights)
samples = all_samples[:,subset]
plt.plot(samples[0], samples[1], '*', alpha=.3)
plot_approx_and_exact_contours(log_density, results['objective'].approx, results['opt_param'],
xlim=[-2, 2], ylim=[-3.25, 2])
[ ]: